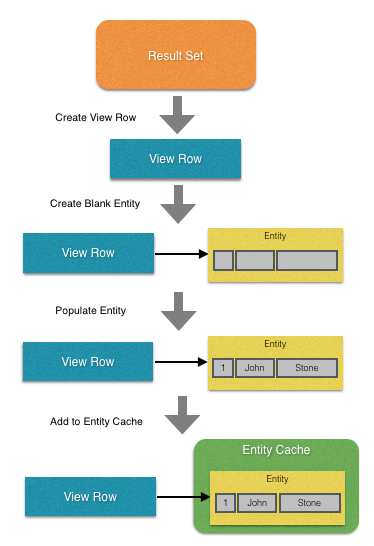
In one of my previous posts I explained the getQueryHitCount view object method. The method is typically invoked by the framework when some UI components, such as tables or tree tables, need to investigate the number of iterator rows in order to size their scroll bar. The method hits database with a SQL query calculating the number of rows. For example, if a view object query is "select * from Currency", then the getQueryHitCount will generate the following query "select count(1) from (select * from Currency)". Off course it has a certain performance impact. Furthermore, in some cases, for example when it comes to programmatically populated view objects, it could be a pretty complicated task to calculate the number of view object rows. Therefore this method is often overridden in order to return -1 instead of performing an expensive query.
So, having done that developers can relax and feel happy since they have prevented the framework from executing needless expensive SQL queries. The application performance improved and everything seemed to be ok.
At some point they came up with an idea to fix one more performance issue. They decided to limit the number of rows to be fetched by any view object in the application. That can be done by specifying the Row Fetch Limit parameter in adf-config.xml:

But unfortunately, having done that, the application slowed down. The log analysis showed that the framework started performing "select count(1) ..." queries again.
If the Row Fetch Limit is setup, the framework doesn't execute the getQueryHitCount when it needs to get an estimated row count. Instead of that, it invokes the getCappedQueryHitCount VO method. The method has the following signature:
The viewRowSet is actually the row set containing the fetched rows, the masterRows is needed to get the parameters in a master-detail scenario, the oldCap is not used, and the cap is actually the value that prevents the database from scanning all rows while performing a "select count ..." query.
So, in our case the cap is going to be 200 and the method is going to generate the following query:
"select count(1) from (select * from Currency where ROWNUM<=201)".
The framework demonstrates the same behavior and invokes getCappedQueryHitCount rather than
getQueryHitCount when the iterator binding property RowCountThreshold comes with some positive value:
By default RowCountThreshold = 0.
So, if we need to avoid that sort of "select count ..." queries as well, we should either override the getCappedQueryHitCount method or set up RowCountThreshold = -1 at the iterator binding level.
That's it!
So, having done that developers can relax and feel happy since they have prevented the framework from executing needless expensive SQL queries. The application performance improved and everything seemed to be ok.
At some point they came up with an idea to fix one more performance issue. They decided to limit the number of rows to be fetched by any view object in the application. That can be done by specifying the Row Fetch Limit parameter in adf-config.xml:
But unfortunately, having done that, the application slowed down. The log analysis showed that the framework started performing "select count(1) ..." queries again.
If the Row Fetch Limit is setup, the framework doesn't execute the getQueryHitCount when it needs to get an estimated row count. Instead of that, it invokes the getCappedQueryHitCount VO method. The method has the following signature:
public long getCappedQueryHitCount(ViewRowSetImpl viewRowSet, Row[] masterRows, long oldCap, long cap)
The viewRowSet is actually the row set containing the fetched rows, the masterRows is needed to get the parameters in a master-detail scenario, the oldCap is not used, and the cap is actually the value that prevents the database from scanning all rows while performing a "select count ..." query.
So, in our case the cap is going to be 200 and the method is going to generate the following query:
"select count(1) from (select * from Currency where ROWNUM<=201)".
The framework demonstrates the same behavior and invokes getCappedQueryHitCount rather than
getQueryHitCount when the iterator binding property RowCountThreshold comes with some positive value:
<iterator Binds="CurrencyView" RangeSize="25" DataControl="AppModuleDataControl" id="CurrencyViewIterator" RowCountThreshold="200"/>
By default RowCountThreshold = 0.
So, if we need to avoid that sort of "select count ..." queries as well, we should either override the getCappedQueryHitCount method or set up RowCountThreshold = -1 at the iterator binding level.
That's it!